
This was no easy feat.
When I tell people I deployed HaloArchives.com by myself, they often don't grasp what that actually means. Let me put it in perspective with some numbers that still make my head spin:
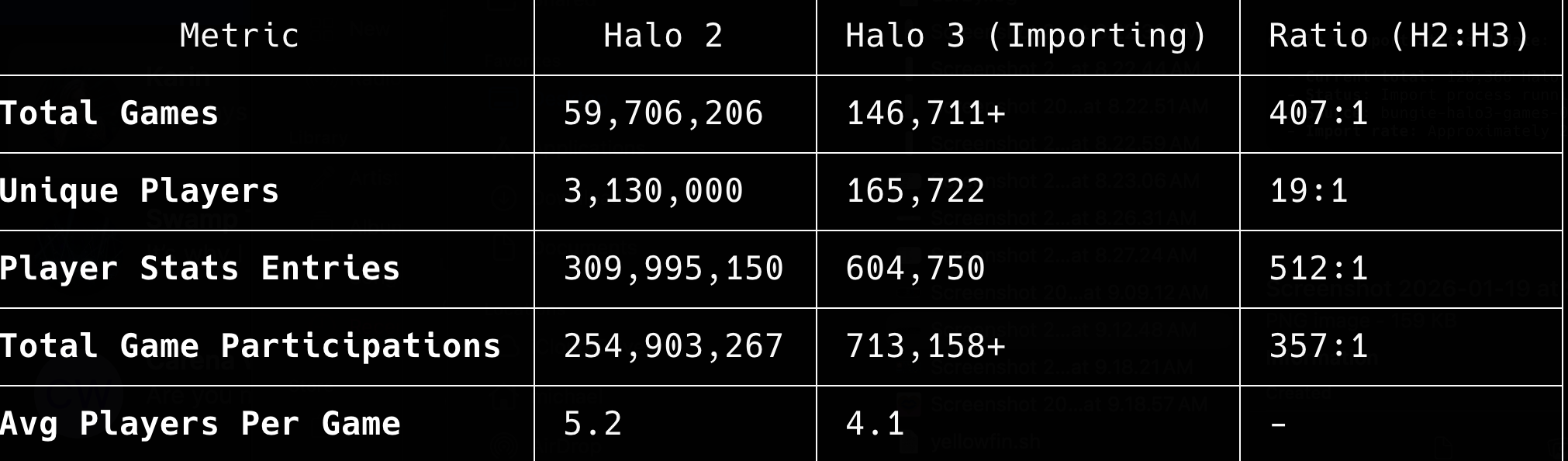
For Halo 2 alone, I'm dealing with 59,706,206 total games, 3,130,000 unique players, 309,995,150 player stats entries, and 254,903,267 total game participations. And that's just one game. The ratios tell the story: Halo 2's dataset dwarfs Halo 3's by factors of 400:1 to 500:1 in some metrics. When you're dealing with over 309 million player stat entries from a single title, you quickly realize this isn't a weekend project. This is industrial-scale data engineering.
I built, deployed, and maintain all of this infrastructure entirely by myself. No team. No DevOps engineers. No dedicated DBAs. Just me, a lot of coffee, and an obsessive need to preserve gaming history before it disappears forever.
This is the story of how I did it, from data acquisition to production infrastructure, and the lessons I learned along the way.
The Vision: Preserving Halo History
The Halo franchise has been a cornerstone of gaming since 2001. Over the years, millions of players have competed in matchmaking, forged custom maps, captured screenshots, and created content. But much of this history exists in fragmented databases, deprecated APIs, and services that are slowly being shut down. I wanted to preserve this history before it disappeared forever.
HaloArchives.com would be different from existing fan sites. Instead of curated content, I wanted raw data: every match, every player stat, every medal earned. I wanted researchers, content creators, and nostalgic fans to be able to explore the complete statistical history of Halo multiplayer.
The scope was ambitious: Halo 2, Halo 3, Halo Reach, Halo 4, Halo 5, and Halo Infinite. Each game had different data structures, different APIs, and different challenges.
Phase 1: Data Acquisition
The first challenge was getting the data. Some of it came from official sources, specifically Bungie's legacy APIs for older games and 343 Industries' APIs for newer titles. But official APIs only tell part of the story. Much of the historical data I needed had been deprecated or was never publicly available.
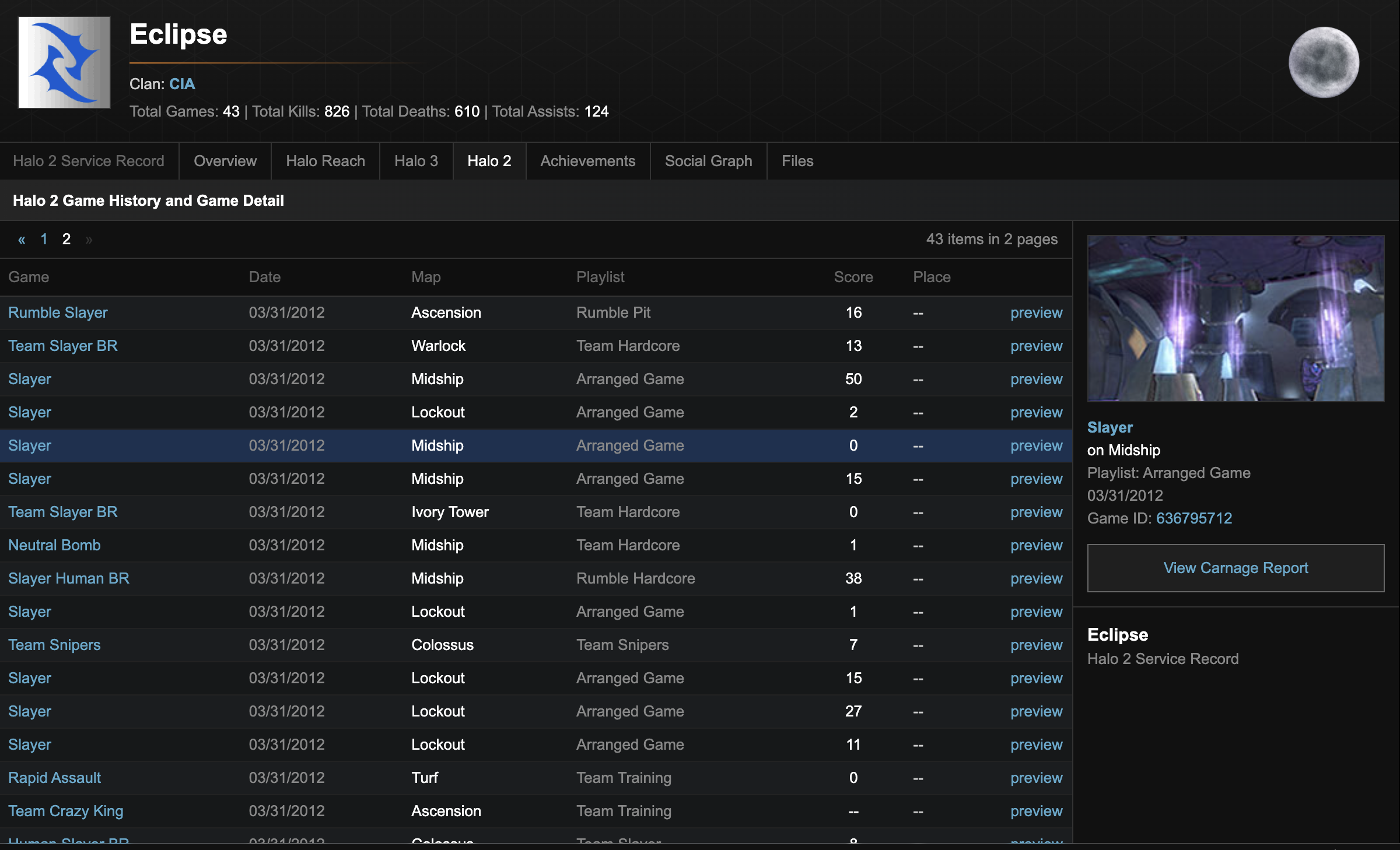
I spent months reverse-engineering data formats, scraping archived web pages, and reaching out to community members who had been collecting data for years. The Halo community is incredibly dedicated, and several community archivists had been quietly preserving match histories and player statistics since the Halo 2 era.
For Halo 2 specifically, I was fortunate to connect with an insider source who had access to data that was never made publicly available. This included internal match records, player statistics, and metadata that most people assumed was lost forever when the original Xbox Live servers shut down in 2010. This exclusive data is a significant part of what makes HaloArchives unique, particularly for the Halo 2 archive which contains records you simply cannot find anywhere else on the internet.
The raw data came in dozens of formats: JSON dumps from API responses, CSV exports from community tracking tools, XML files from legacy Bungie.net exports, SQLite databases from third-party stat trackers, plain text files with custom delimiters, and binary files that required reverse engineering.
Each source had its own schema, its own quirks, and its own data quality issues. Some sources had duplicate records. Others had missing fields. Many had inconsistent formatting that changed over time as the original systems evolved.
The Emblem Generator
One of the most challenging aspects of data acquisition was recreating player emblems. In Halo 2 and Halo 3, every player had a customizable emblem, which was a combination of a foreground icon, background shape, and color scheme that served as their visual identity. These emblems weren't stored as images; they were stored as numeric codes representing the combination of components.
The problem? The original emblem rendering code was proprietary and lost to time. I had the emblem codes for millions of players, but no way to actually display them. To my knowledge, no public emblem generator exists on the internet. The tools simply aren't out there. So I built my own from scratch.
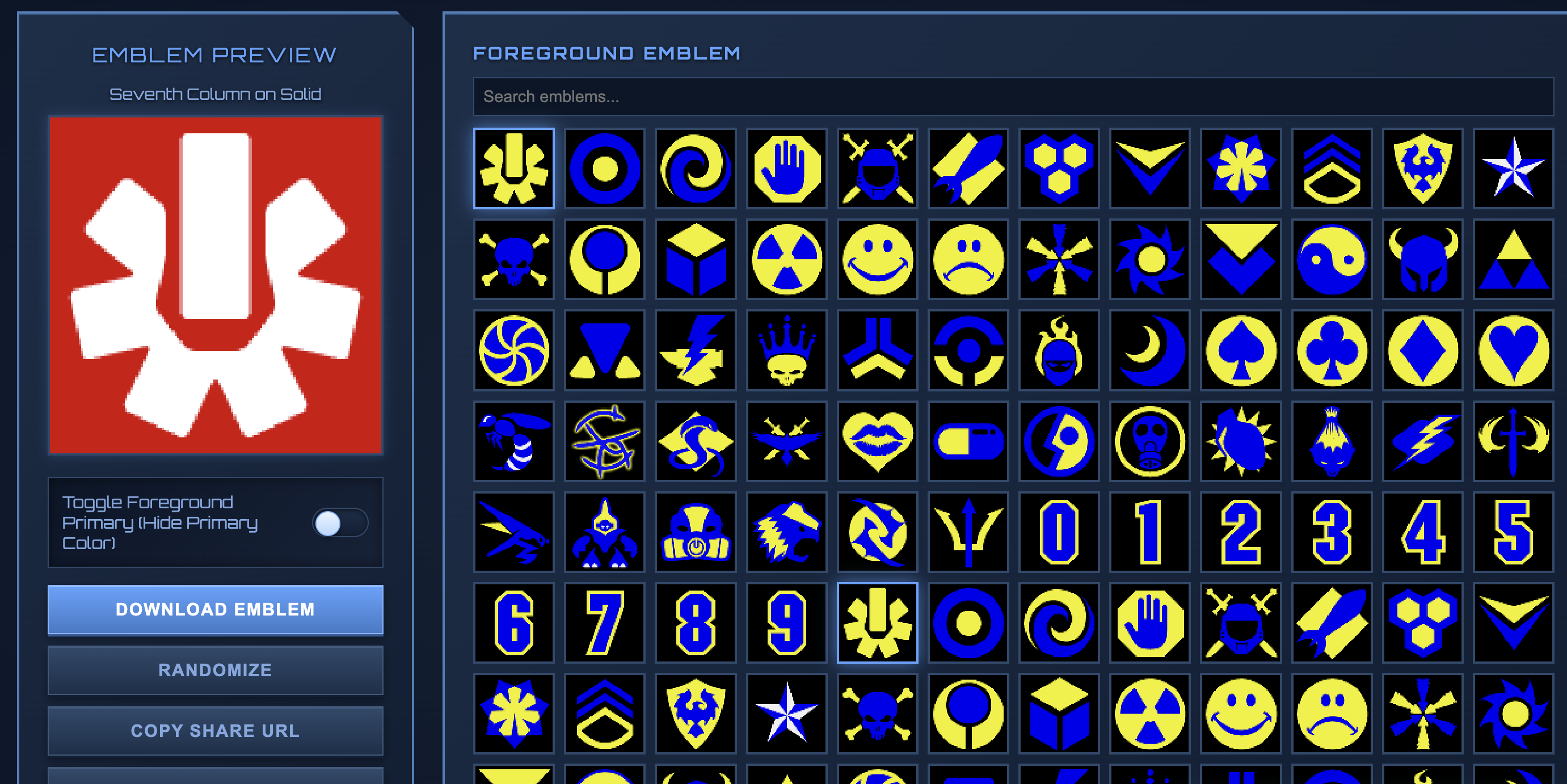
I started by cataloging every emblem component from the original games, painstakingly extracting foreground icons, background shapes, and the exact color palettes Bungie used. Then I wrote a renderer that takes the numeric emblem codes and composites the correct layers with the correct colors in the correct order. The result is pixel-perfect recreation of player emblems that haven't been visible since Xbox Live shut down the original services.
This emblem generator now powers every player profile on HaloArchives.com, bringing back a piece of visual identity that many players thought was gone forever. Users can also create their own emblems, download them, randomize combinations, and share them via URL. This functionality hasn't existed publicly since Bungie.net was deprecated.
Bringing Back Fileshare
One of the most beloved features of Halo 3 and Halo Reach was the File Share, a place where players could save and share their screenshots, game clips, map variants, and custom game modes. When Bungie.net shut down its legacy services, millions of these files became inaccessible. Players lost screenshots of epic moments, carefully crafted Forge maps, and custom game types they'd spent hours perfecting.
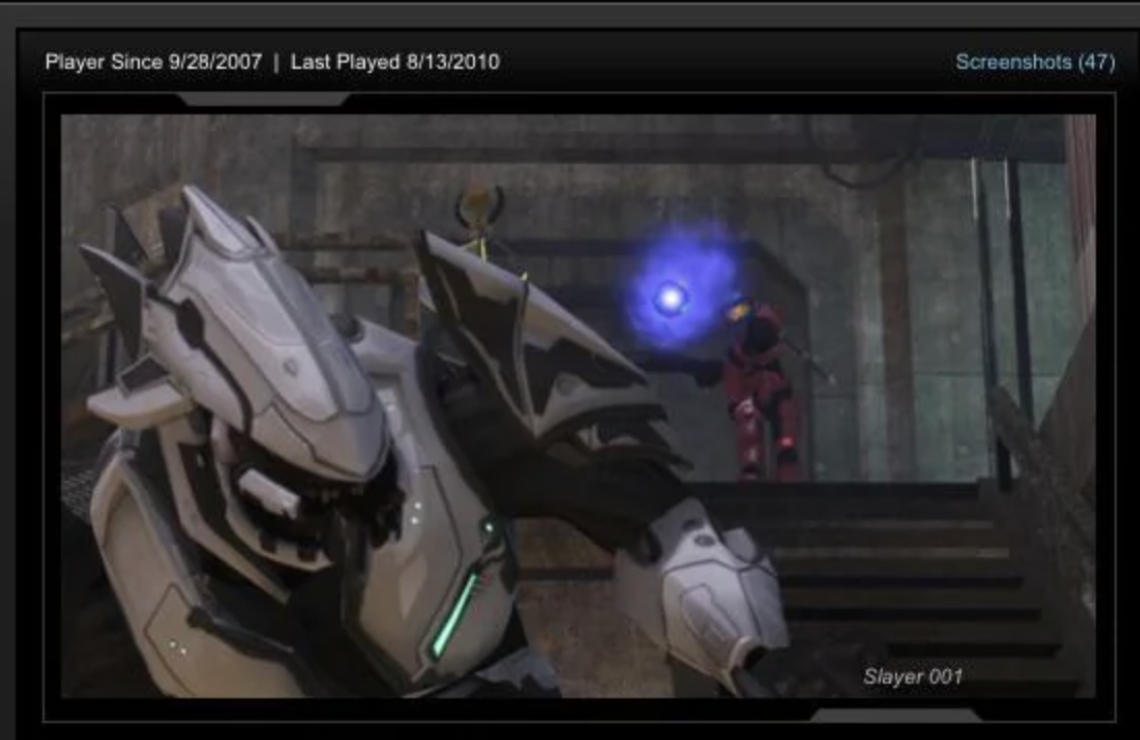
I managed to recover and archive a massive collection of these files. Players can now browse their old File Shares, see screenshots they took over a decade ago, and relive those moments. The interface shows when they first played, their last activity, and all their saved content. Some players have 47 or more screenshots preserved, each one a frozen moment from gaming sessions that happened 15+ years ago.
Community Forums
Preserving data is only half the battle. You also need to give the community a place to gather. I built full-featured forums from scratch, complete with categories for every aspect of Halo: campaign discussions, multiplayer strategy, forge creations, lore debates, and of course "The Flood" for off-topic banter.
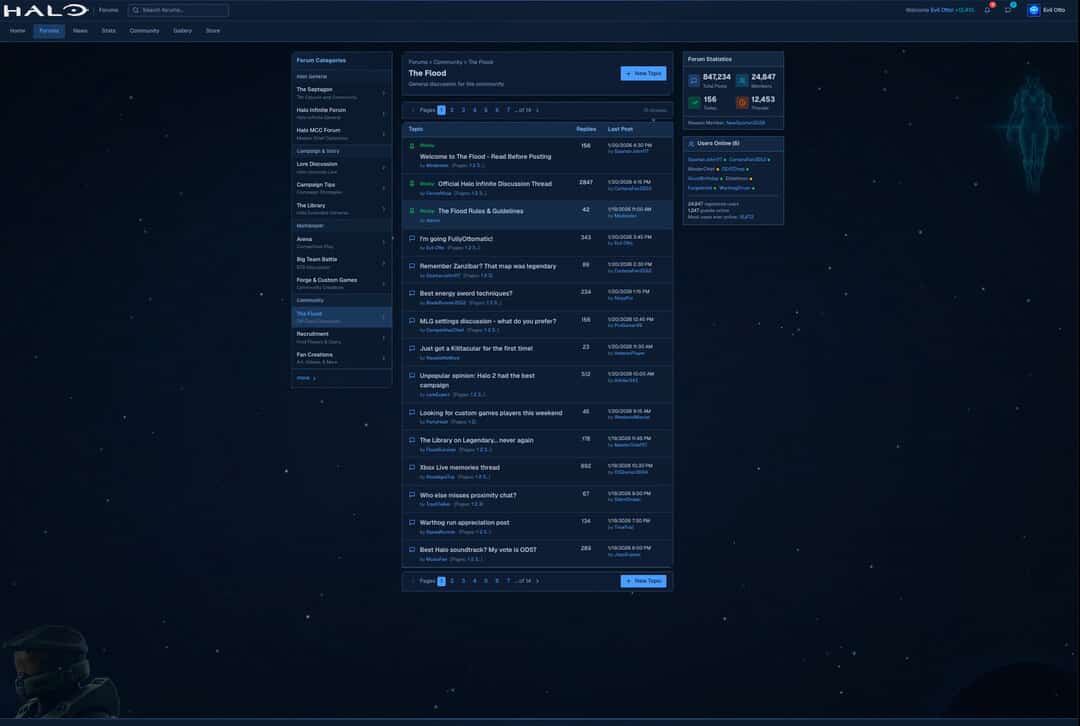
The forums aren't just a nice-to-have. They're essential for data preservation. Community members help identify data gaps, verify accuracy, and contribute their own archived content. With over 847,000 posts, 24,000 members, and 12,000 active threads, the forums have become a thriving hub where veterans share memories and newcomers discover the rich history of Halo multiplayer.
And I'm glad I'm bringing this back to the Halo community at large!
Social Graph
One of the most interesting features I built is the Social Graph, a way to see which players you played with the most over your entire Halo career. The archive contains enough match data to reconstruct these relationships across millions of games.
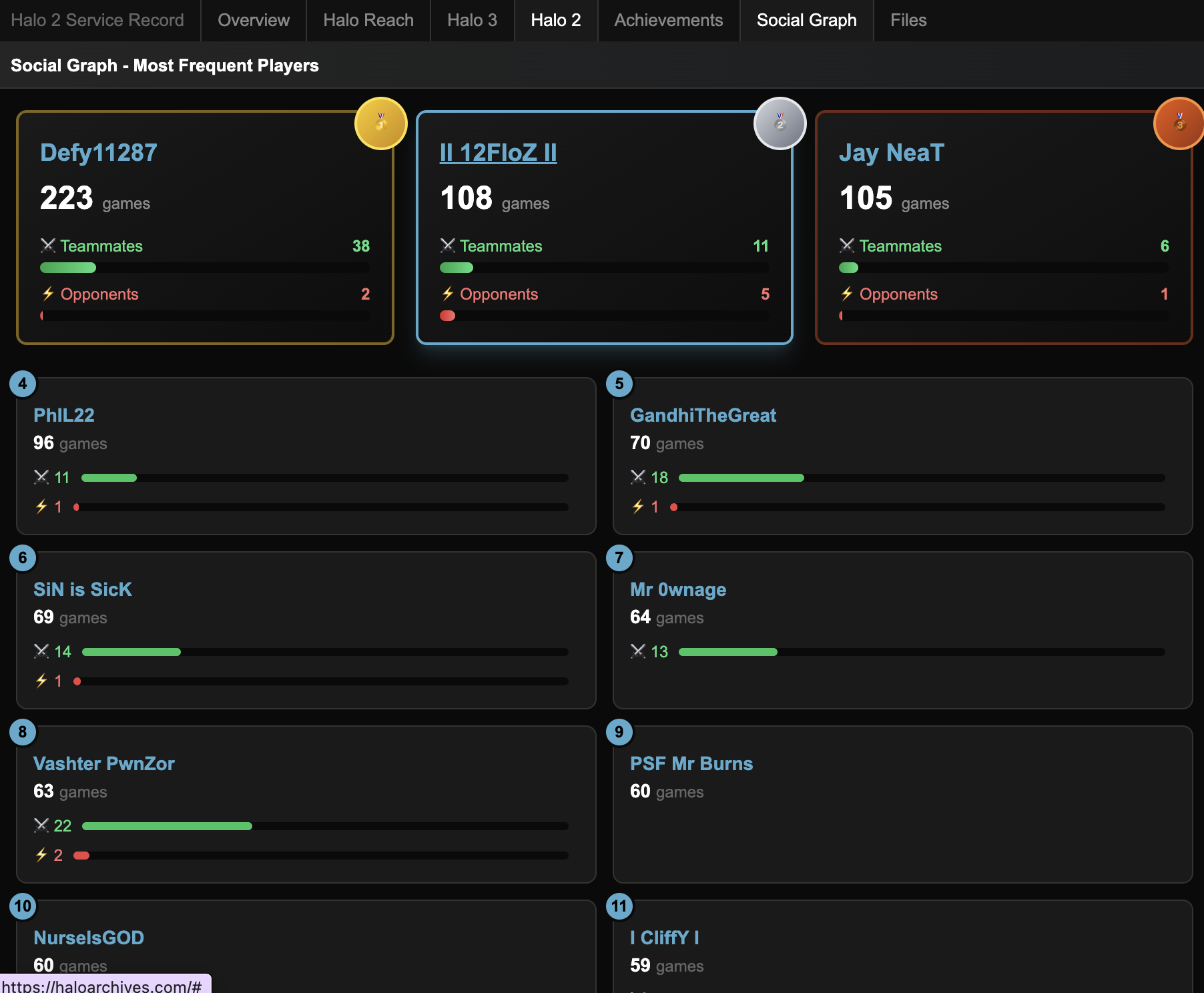
For each player, you can see a ranked list of who they played with most frequently, how many games they shared, and whether those players were typically teammates or opponents. The top players get gold, silver, and bronze medals, and you can see at a glance whether someone was your regular squad mate or your sworn rival. It's a nostalgic trip seeing names you haven't thought about in years pop up, people you used to play with every night who you've long since lost touch with.
Rank Preservation
The Halo 2 ranking system was legendary. It wasn't just about numbers; it was about the iconic visual ranks that players worked months or even years to achieve. The Moon, the Sun, the Lightning Bolt, the numbered ranks from 1-50. These symbols meant something. They were a badge of honor, proof that you'd put in the time and had the skill to back it up. When Xbox Live shut down for the original Xbox, these ranks disappeared with it.
Luckily for everyone, I have high resolution vector files of the famously designed Halo 2 ranks. Here's some examples:
Every player profile on HaloArchives displays their original Halo 2 rank exactly as it appeared back in the day. Whether you were a level 35 grinder, hit the coveted 40s, or achieved one of the special icon ranks like the Sun or Moon, your rank is preserved and displayed prominently. It's one of the most requested features from the community, and seeing these ranks rendered in high quality after all these years brings back a flood of memories for anyone who lived through that era of competitive Halo.
SplitArchive Import Process
One question I get asked frequently: how does the splitting of zip files where the data lives from the source actually work? The raw data dumps I received were massive, often too large to handle as single files. They came as split archives, sometimes spanning dozens of parts.
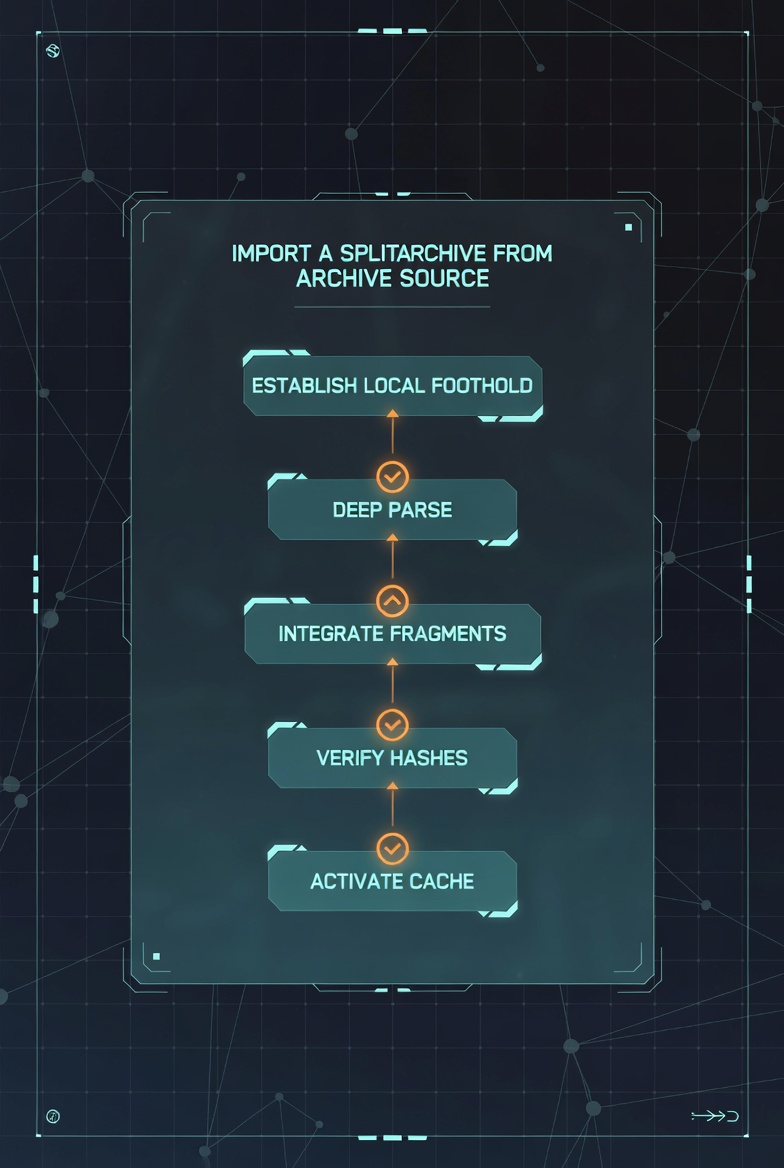
I built a custom import pipeline specifically for handling these split archives. First, I establish a local foothold by downloading and staging all the split parts. Then comes the deep parse phase where I scan the archive structure and identify all the data fragments inside. The integrate fragments step reassembles the split pieces back into coherent data files. This is where the magic happens, stitching together parts that were split mid-record. Hash verification ensures nothing got corrupted during transfer or reassembly. Finally, the data gets loaded into a local cache for fast access during the ETL process. This pipeline saved me countless hours of manual file management and ensured data integrity across terabytes of archived content.

Here's what the actual processing looks like in action. Each line represents a batch of 500 records being processed, showing the running totals of games added and player records ingested. You can also see the "skipped" count, which tracks duplicate or malformed records that get filtered out. Watching these numbers tick up in real-time over hours (sometimes days) never gets old.
Phase 2: Data Processing Pipeline
Processing 70 million lines of data isn't something you do with a simple script. I needed a robust ETL (Extract, Transform, Load) pipeline that could handle the volume and variety of data sources.
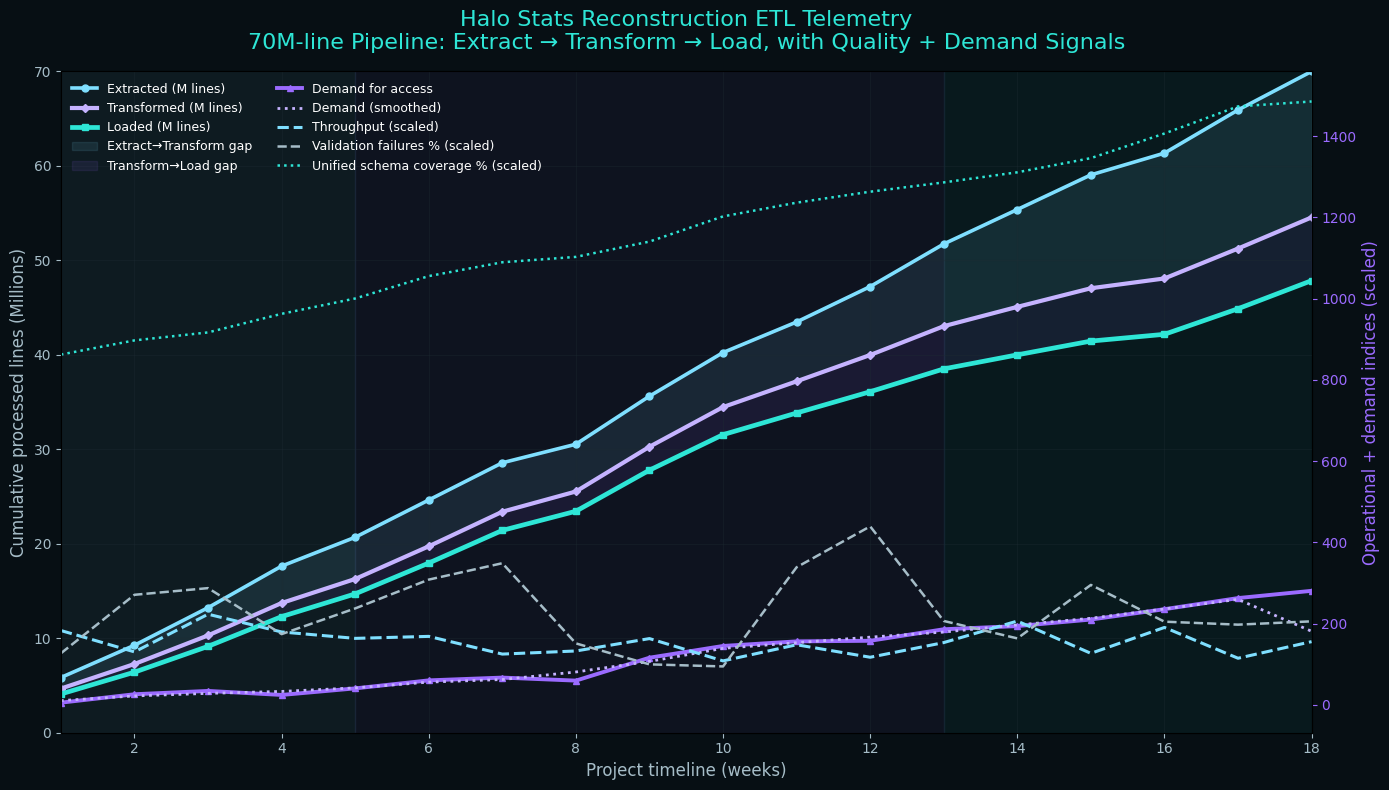
I built the pipeline using Python with a combination of pandas for data manipulation, Apache Spark for distributed processing of the largest datasets, and custom scripts for format-specific transformations. The pipeline ran on a cluster of machines I provisioned specifically for this project.
The transformation phase was the most complex. Each game had different concepts of "matches," "players," "teams," and "statistics." Halo 2's stat tracking was primitive compared to Halo 5's detailed performance metrics. I needed to create a unified schema that could represent data from all games while preserving the unique details of each.
My unified schema covered players (gamertag history, account linking across games, aliases), matches (game mode, map, date, duration, team compositions), performance metrics (kills, deaths, assists, medals, accuracy, damage dealt), and metadata (game version, playlist, skill ratings, seasonal data).
The normalization process alone took weeks. I wrote custom parsers for each data source, validation rules to catch anomalies, and reconciliation logic to handle conflicts between overlapping sources.
Phase 3: Database Architecture
With 70 million lines of normalized data, database choice was critical. I evaluated several options.
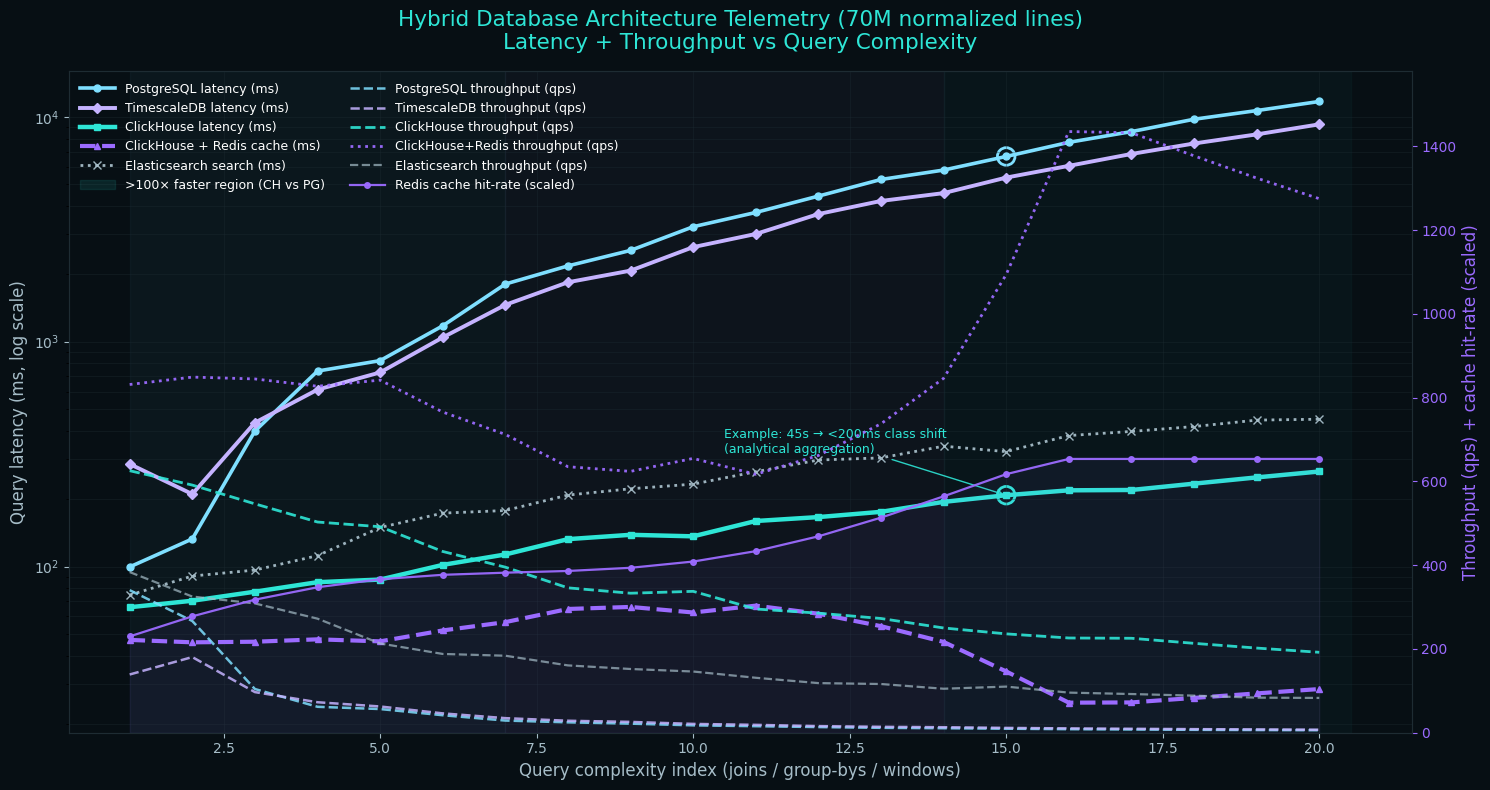
PostgreSQL was my initial choice for its robust feature set and reliability. However, queries across the full dataset were slow without aggressive indexing, and the storage requirements were substantial.
TimescaleDB (PostgreSQL extension) helped with time-series queries for match histories, but added complexity to the deployment.
ClickHouse emerged as the winner for analytical queries. Its columnar storage and vectorized execution made complex aggregations across millions of rows blazingly fast. A query that took 45 seconds in PostgreSQL completed in under 200 milliseconds in ClickHouse.
The final architecture uses a hybrid approach: ClickHouse handles analytical queries like leaderboards, statistics, and historical trends; PostgreSQL manages transactional data including user accounts, favorites, and comments; Redis provides caching for frequently accessed data; and Elasticsearch powers full-text search across player names and match metadata.
Phase 4: API Development
With the data stored, I needed an API to serve it. I built a REST API using Go for its performance characteristics and excellent concurrency model. The API handles thousands of requests per second during peak traffic.
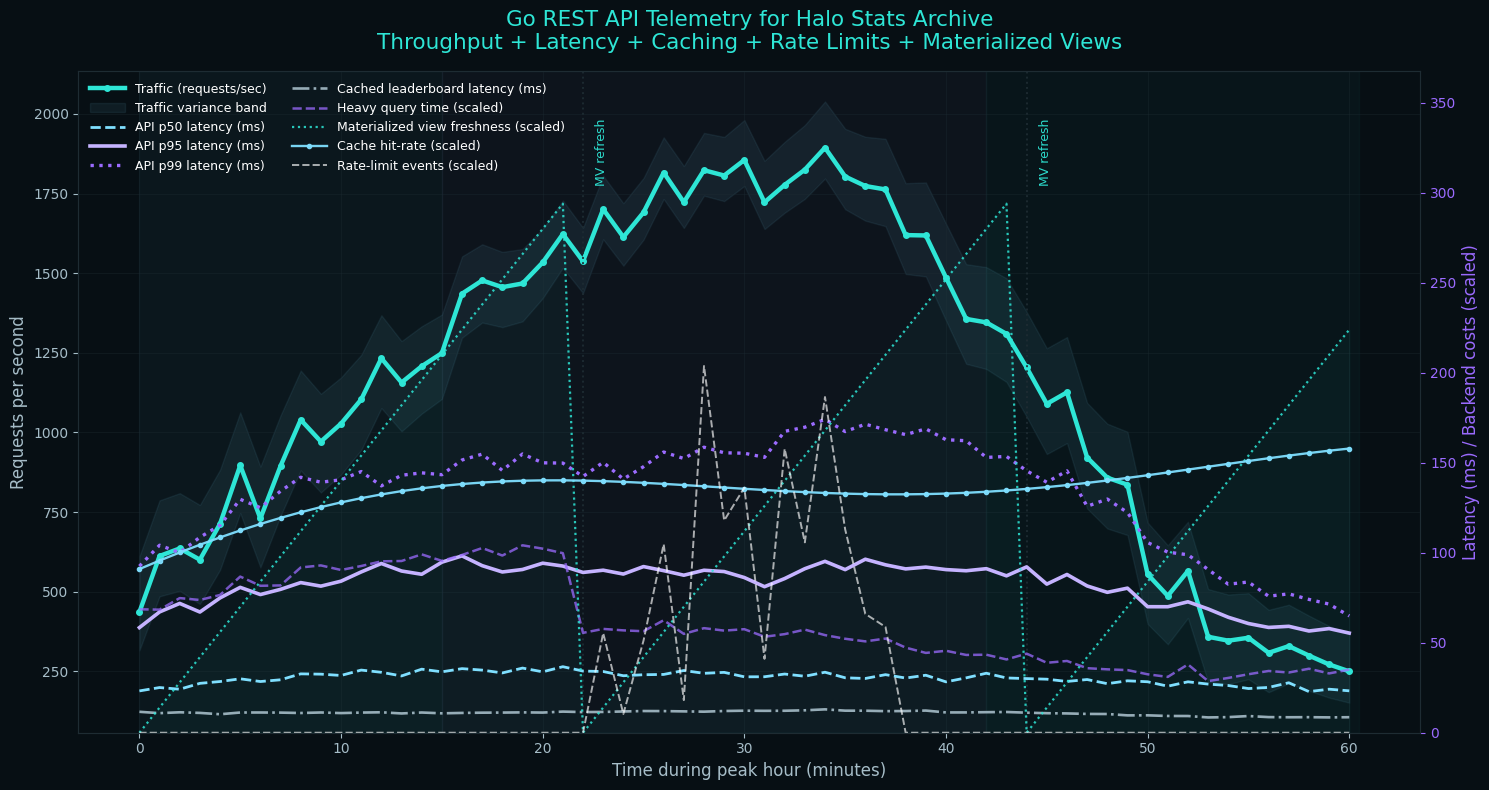
The API exposes endpoints for player profiles with career statistics across all games, match history with detailed performance breakdowns, leaderboards with various filters and time ranges, search functionality for finding players and matches, and comparison tools for analyzing multiple players.
Rate limiting, caching, and query optimization were essential. Some queries, like calculating all-time leaderboards, could potentially scan billions of rows. I implemented materialized views that pre-compute common aggregations and refresh on a schedule.
Phase 5: Frontend Development
The frontend needed to handle complex data visualizations while remaining fast and accessible. I chose Next.js for its server-side rendering capabilities and excellent developer experience.

The frontend includes comprehensive player profiles with charts showing performance over time, a searchable and filterable match browser for exploring match histories, dynamic leaderboards with multiple sorting options and filters, a comparison tool for side-by-side analysis of multiple players, and a timeline view providing visual representation of a player's gaming history.
I used Recharts for data visualization, implementing custom charts for kill/death ratio trends over time, medal distribution breakdowns, win rate by game mode and map, and skill rating progression.
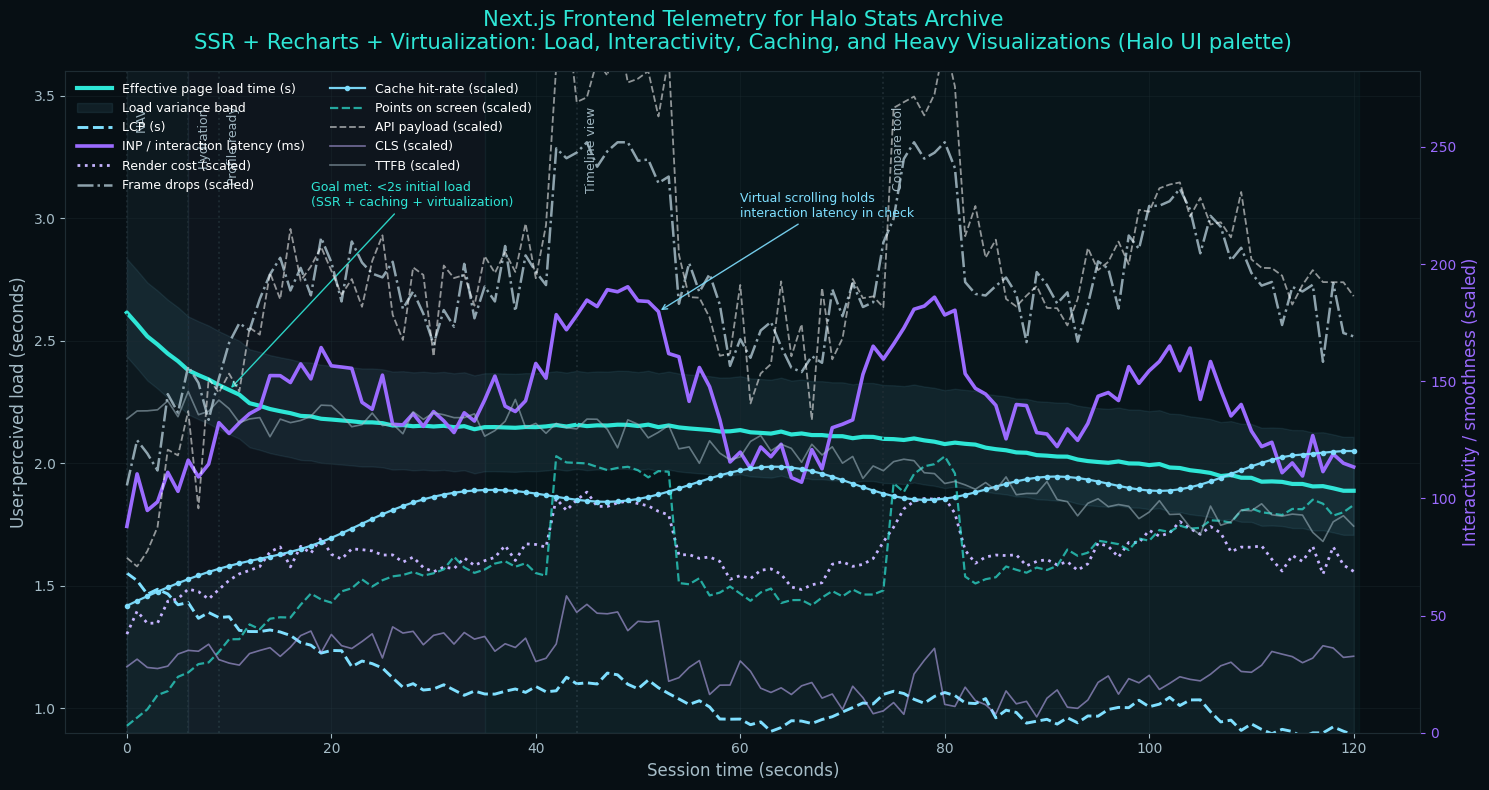
Performance optimization was crucial. With pages that could display thousands of data points, I implemented virtual scrolling, lazy loading, and aggressive caching. Initial page loads complete in under 2 seconds even for the most data-heavy profiles.
Phase 6: Infrastructure and Deployment
Deploying HaloArchives.com required careful infrastructure planning. I chose a hybrid approach.
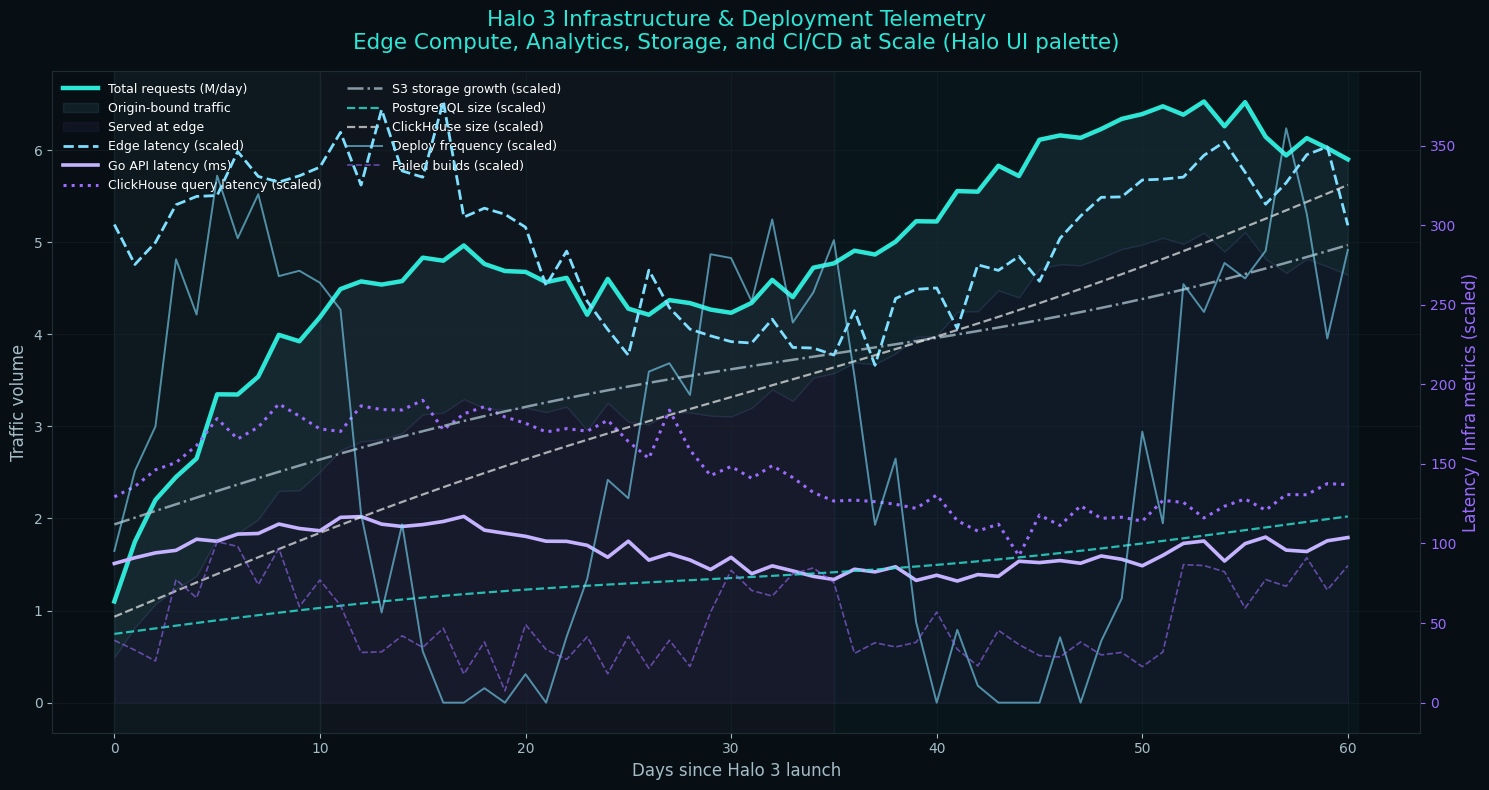
For compute, I use Vercel for the Next.js frontend with edge deployment for global performance, dedicated servers for the Go API colocated for database proximity, and ClickHouse Cloud for the analytical database. Storage consists of S3-compatible object storage for static assets and backups, managed PostgreSQL for transactional data, and a Redis cluster for caching. For CDN and security, I rely on Cloudflare for DDoS protection and edge caching, Let's Encrypt for SSL certificates, and custom rate limiting at the API layer.
The deployment pipeline uses GitHub Actions for CI/CD. Code changes trigger automated tests, passing builds deploy to a staging environment, manual promotion to production happens after verification, and database migrations run automatically with rollback capability.
What's Next
HaloArchives.com is a living project that grows every single week. New data dumps are happening on a weekly basis as I continue to process, clean, and ingest more historical Halo data from various sources. Every week brings more player profiles, more match histories, and more files recovered from the archives.
Beyond the data, the website itself is constantly improving. The Emblem Generator recently received updates to support additional emblem combinations and improved color accuracy. The Community Forums are getting new features like enhanced search, better moderation tools, and quality-of-life improvements based on user feedback. The File Share browser is being expanded to support more file types and better preview functionality.
Coming soon: real-time match tracking integration for Halo Infinite, a dedicated Halo 2 Vista section with its unique statistics, historical analysis tools for researchers studying gaming trends, a public API for developers who want to build on top of the archive, achievement tracking and completion statistics, clan and team history pages, and a mobile-optimized experience for checking stats on the go.
The project is also exploring partnerships with content creators, Halo YouTubers, and esports organizations to provide statistical analysis for competitive Halo coverage. If you're interested in collaborating or have data to contribute, reach out through the forums.
Conclusion
Deploying HaloArchives.com by myself with over 70 million lines of data was one of the most challenging technical projects I've undertaken. It required expertise across the full stack: data engineering, backend development, frontend design, infrastructure operations, and security.
But more than technical skills, it required patience, persistence, and passion. There were countless late nights debugging data inconsistencies, optimizing slow queries, and refactoring code that almost worked. The Halo community's enthusiasm kept me motivated through the difficult stretches.
The result is a comprehensive archive that preserves an important part of gaming history. Every match, every medal, every clutch play is now preserved for future generations of Halo fans to explore and appreciate.
If you're considering a similar large-scale data project, my advice is simple: start small, automate early, and don't underestimate the value of community. The technical challenges are solvable; the human challenges of building something people actually want to use are harder.
Sign up now at haloarchives.com and come explore your Halo history. Your account will be reviewed before activation to keep the community safe and spam-free.
If your account gets denied for any reason, you'll see a message like the one above. This helps maintain the quality of the community. If you believe your denial was a mistake, reach out through the contact options on the site.